晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
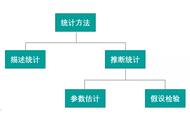
线性代数和概率论是机器学习的必备基础课程。前几天,量子位已经推荐了一个可以互动的线性代数课程。
最近,有位印度小哥Nimish Mishra在Medium上分享了一篇概率论基础知识,也是一篇零基础的入门课程。

这篇文章提到了很多基本概念和重要的变量分布。其中有些概念,比如协方差,可以帮助我们理解机器学习中变量之间的关系。
这位小哥提到的指数分布,则在神经网络调参中有着直接的应用。
下面,就让我们一起来跟他学习一下吧。
概率论中的基本概念我们先从掷硬币开始谈起。
随机变量可以是离散的,也可以是连续的。比如抛硬币的结果就是一个离散的随机变量,而降雨量就是一个连续的随机变量。
为了方便起见,我们可以定义一个变量x,当硬币出现正面时x=1,当硬币出现反面时x=0。对于降雨量这个随机变量而言,我们只能定义x是一个大于0的实数。
随机变量的结果虽然不可预知,但并不是完全不可捉摸的,它有一定的规律性,这就是概率分布函数。
对于离散变量,它是x的概率为p,我们可以定义f(x)=p。在抛硬币这个问题中,f(0)=1/2,f(1)=1/2。
对于连续变量,x的取值是连续的,我们不能再说x等于某个值的概率是多少,而是用一个概率密度函数来表示它,当x取值在a和b两个数之间时,它的概率可以用以下积分结果表示:

弄清楚概率分布函数后,接下来我们就可以定义这些量:期望值、方差、协方差。
期望值又叫平均值,一般用μ表示。以离散随机变量为例,把变量的值和对应的概率相乘,然后把所有乘积相加起来,就是期望值:

方差用来衡量随机变量偏离平均值的程度,它是变量X减平均值μ的平方——(X-μ)^2——的平均值。