1.社会调查研究的步骤:1.确定课题。2.了解情况。3.建立假设。4.确定概念和测量方法。5.涉及问卷。6.试填问卷。7.调查实施。8.校核与登录。9.统计分析与命题的检验。资料的整理归纳分析以及如何收集资料正是统计分析所要谈论的内容。
2.社会调查资料的特点:随机性和统计规律性。
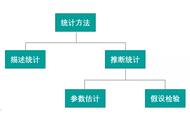
3.怎样选用统计分析方法:1.全面调查和非全面调查。2.单变量和多变量。3.变量层次.
4.分布概念:指一个概念或变量,它的各个情况出现的次数或频次,又称频次分布。表现形式:数对的集合.
5.变量取值的要求— ⑴变量取值必须完备; ⑵变量取值必须互斥。
6.统计表:是用表格形式来标识前面所说变量的分布。它不需要文字叙述,就能反应出资料的特性以及资料之间的关系,在编印,传递方面有很大优点,比统计表更精确,但不及统计图直观。
7.统计表必须具备的内容:1.表号。2.表头。3.标识行。4.主体行。5.表尾。
8.根据变量的层次,可以选择以下不同的统计图形:定类变量:圆瓣图、条形图。定序变量:条形图。定距变量:直方图、折线图。
9.圆瓣图:是将资料展示在一个圆的平面上,通常用圆形代表现象的总体,用圆瓣代表现象中一种情况,其大小代表变量取值在总体中所占的百分数。
10.条形图:是用长条的高度来表示资料类别的次数或百分数。定类:离散。定序:离散或紧挨着的。
11.直方图:直方图从图形来看,也是紧挨着的长条形所组成,它与条形图不同,宽度有意义,一般来说,直方图是以长条的面积来表示频次或相对频次,而条形的长度。即纵轴高度表示是频次密度或相对频次密度。频次密度=频次/组距。
12.折线图:如果用直线连接直方图中条形顶端的中点,就是折线图。折线图可使资料的频次分布趋势更一目了然。
13.累计图和累计表:表示的是大于某个变量值的频次是多少或小于某个变量值的频次是多少。
14.众值:就是用具有频数最多的变量值来表示变量的集中值。
15.中位值:是数据序列之中央位置之变量值。未分组:N为奇数时:中位值等于n 1/2. N为偶数时:中位值等于中间两变量和/2. 根据频次分布求中位值:中位值等于频次的和 1/2.中位值等于求出所对应值所在的区域。分组:1.计算出累计频次,得到累计百分比。2.确定最高频次所在组。
均值:总体各单位数值之和除以总体单位数目所得之商。
统计分析中习惯以X 来表示。
离散趋势测量法:
1. 异众比率:非众值在总数N中所占的比例。Fm0=众数的频率。
2. 极差:=观察的最大值-观察的最小值。
3. 四分互差:q=q75-q25 , q50的位置=n 1/2.q25的位置=n 1/4.q74的位置=3(n 1)/2、、分组资料求:
4. 方差与标准差
5. 众值。中位值和均值的比较:1.众值:定类。定序和定距变量:异众比率。2.中位值:定类和定序:极差和四分互差。3.均值:定距:方差或标准差。
第三章:概率
概念:概率分布,反映的是随机变量一共有多少种可能取值,以及各种取值所出现的概率是多少。 2.形式:可表示为数对的集合。 3.要求:随机变量的取值必须满足完备性和互斥性。
数学期望 含义: 数学期望是总体均值,即总体某一随机变量各项取值的加权平均值,它只是一个理论值,是我们所期望的均值。
第五章:
1.正态分布的三个特征:1.一个高峰:曲线是单峰,有一个最高点。2.一个对称轴:对称轴是直线x=u。3.一个渐近线:横轴为渐近线。
均值:决定左右方向。方差:决定高矮胖瘦。
2.正态分布的概率密度表达公式:
3.极限定理:凡采用极限的方法所得出的一系列定理。统称极限定理。可分为两类:一类是研究在什么条件下随机事件可以转化为不可能事件或必然事件即有关阐明大量随机现象平均结果的稳定性的一系列定理。成为大数定理。第二类:是研究在什么条件下,随机变量之和的分布可以近似为正态分布,称为中心极限定理。
4.大数定理和中心极限定理:贝努里大数定理表明,在相同条件下进行多次观察时,随机事件发生的频率有接近其概率的趋势。大数定理:从一个特定的总体中抽取出所有可能的样本(样本容量相同),如果样本容量足够大,那么这些样本的均值的分布将趋近于正态分布。
意义:为统计推论中用抽样成数来估计总体成数提供了理论依据
第六章参数估计
1.统计推论:统计推论是根据局部资料(样本资料)对总体的特征进行推断。 即,从被研究现象的总体中按照随机原则抽取一部分个体进行调查,并依据调查结果对总体的数量特征作出具有一定可靠程度的估计,以达到认识总体的一种统计方法。
2.总体:研究对象的全体。总体的数量指标可以看作随机变量。
3.样本:按照一定方法从调查总体中抽取出来的部分调查对象的集合。
4.统计量:样本中的每一个个体资料所反映的数据是一个随机变量。那么,从总体中抽取容量为n的样本,可以看做是n个相互独立且分布相同的随机变量ξ1,ξ2,…,ξn。则该随机变量的任何函数f(ξ1,ξ2,…,ξn)也是随机变量。则该函数叫作统计量。
5.抽样分布: 抽样分布,指从一个特定的总体中抽取出所有可能的容量相同的样本时,这所有样本的统计值的分布情况。实际就是研究统计量的数字特征:均值和方差。
6.置信区间和置信度:在样本容量一定的情况下,置信区间和置信度是相互制约的。置信度越大,则相应的置信区间也越宽。
第七章
1.统计假设: 可以通过抽样调查获得的数据来直接验证的假设。假设检验(统计假设检验),即通过样本资料对总体的某种假设进行检验。 只有通过假设检验,才能用样本资料来科学地推论总体。
2.原假设和备则假设:又称虚无假设,用H0表示。它是根据已有资料或周密考虑后建立的关于总体中不存在某种特征或状态的假设。 备则假设又称研究假设。用H1表示。它是与原假设相反的假设,即关于总体中存在某种特征或状态的假设
3.假设检验的基本原理:假设检验的依据是小概率原理。 小概率原理,全称“小概率事件不可能原理”,指对于发生概率很小的事件,在一次观察(或抽样)中是不可能发生的;如果在一次观察(或抽样)中出现了小概率事件,则认为事件的发生概率实际上并不小。
4.假设检验的步骤和两类错误:1.根据实际问题做出假设。2.根据样本构成合适的,能反应H0的统计量,并在H0成立的条件下确立统计量的分布。3.根据问题的需要,给出小概率α的大小,并根据2.3.点求出拒绝域和临界值。4.根据以上三步骤建立起来的具体检验标准,用样本统计量的观测值进行判断。若样本统计量的值落入拒绝域,则拒绝H0,接受备则假设H1.否则接受H0。
5.两类错误: 1.第一类错误,即弃真的错误。拒绝原本正确的原假设H0,导致推断结论错误。 前提:原假设是正确的。
2.第二类错误,即纳伪的错误。接受了原本错误的原假设H0,则导致了另一种推断错误。 前提:原假设是错误的。
一、列联表的涵义:列联表是将两个或多个定类变量的观测数据分别按照它们的不同取值进行联合分类时所列出的频数(或频率、概率)表。
二、列联表中变量的分布:(一)联合分布 对于列联表中,当x=xi,y=yj时的频次为Nij,写作(xi,yj,Nij)。所有Nij的分布称作联合分布。 (二)边缘分布 在列联表中,只研究其中一个变量不同取值的分布,而不论另一个变量的取值,这样的分布就是边缘分布。(三)条件分布 在列联表中,当一个变量取固定值时,另一个变量不同取值的频率(概率)分布情况,就是条件分布。
三、2×2表— Φ系数和Q系数
2×2表:列联表中两个变量的取值都只有两个。
1.Φ系数的形式和取值范围, Φ∈[-1,1]
2. Q系数的形式和取值范围, Q∈[-1,1]
四、r×c列联表的相关系数
r×c表:列联表中两个变量中至少有一个变量的取值为三个或三个以上。
,