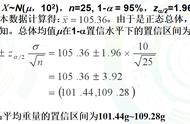今晚重温下数据统计,学习以下内容:
1、对给定数据进行探索性数据分析。
2、计算描述性统计数据并绘制直方图。
3、使用 scipy 库计算置信区间、Z-score和 T-score。
01、几个名词介绍置信区间(confidence interval):即误差范围。
用(a, b)表示,a和b的确切数值取决于事件对于“该区间包含总体均值”这一结果的可信程度。
置信区间在频率学派中间使用,其在贝叶斯统计中的对应概念是可信区间(credible interval)

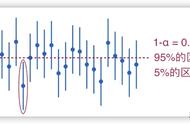
从正态分布产生的50个样本中得出的50个置信区间
置信水平(Confidence level):即置信区间包含总体平均值的概率多大。
例如,95%的置信水平指的是100个置信区间有95个包含了总体平均值。置信水平越高,区间越宽,置信区间包含总体统计量的几率越大,但置信区间太宽,则会失去意义。常用置信水平为95%。
我们常犯一个概念性错误,是将基于观测到的数据所同样构造的置信区间的置信水平,误认为是它包含真实未知参数的真实值的概率。正确的理解是:置信水平只有在描述这个同样构造置信区间的过程(或称方法)的意义下才能被视为一个概率。
Z分数:
z分数(z-score),也叫标准分数(standard score)是一个数与平均数的差再除以标准差的过程。在统计学中,标准分数是一个观测或数据点的值高于被观测值或测量值的平均值的标准偏差的符号数。
z分数可以回答这样一个问题:"一个给定分数距离平均数多少个标准差?"在平均数之上的分数会得到一个正的标准分数,在平均数之下的分数会得到一个负的标准分数。z分数是一种可以看出某分数在分布中相对位置的方法。
T分数:
T分数是原始分数的导出分数。把原始分数转换成标准化分数为线性转换,Z分数与原始分数的分布形状相同,原始分数为正态分布,则Z分数也为正态分布。
原始分数如果不是正态分布,如何使导出分数为正态分布呢?这时可先把原始分数转换成百分等级,而后再把百分等级转换成标准正态分布的z值,从而迫使导出分数z服从均数为0、标准差为1的正态分布,叫做正态化的标准分数。

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('Q7.csv')
df.head()
输出:
Unnamed: 0 | Points | Score | Weigh | |
0 | Mazda RX4 | 3.90 | 2.620 | 16.46 |
1 | Mazda RX4 Wag | 3.90 | 2.875 | 17.02 |
2 | Datsun 710 | 3.85 | 2.320 | 18.61 |
3 | Hornet 4 Drive | 3.08 | 3.215 | 19.44 |
4 | Hornet Sportabout | 3.15 | 3.440 | 17.02 |
df.describe()
输出:
Points | Score | Weigh | |
count | 32.000000 | 32.000000 | 32.000000 |
mean | 3.596563 | 3.217250 | 17.848750 |
std | 0.534679 | 0.978457 | 1.786943 |
min | 2.760000 | 1.513000 | 14.500000 |
25% | 3.080000 | 2.581250 | 16.892500 |
50% | 3.695000 | 3.325000 | 17.710000 |
75% | 3.920000 | 3.610000 | 18.900000 |
max | 4.930000 | 5.424000 | 22.900000 |
df['Weigh'].mode()
输出:
0 17.02
1 18.90
Name: Weigh, dtype: float64
df['Weigh'].var()
输出:
3.193166129032258
df['Weigh'].std()
输出:
1.7869432360968431
df['Weigh'].max() - df['Weigh'].min()
输出:
8.399999999999999
sns.boxplot(df)
输出:

sns.scatterplot(df)
输出: