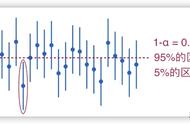
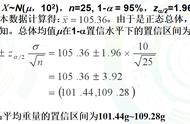import numpy as np
from scipy import stats
sm= 200 # 样本均值
ss= 30/np.sqrt(200) # 标准差
ci94 =stats.norm.interval(confidence = 0.94, loc=sm, scale=ss)
print('94% 置信水平的置信区间为', np.round(ci94,2))
94% 置信水平的置信区间为 [196.01 203.99]
ci98 =stats.norm.interval(confidence = 0.98, loc=sm, scale=ss)
print('98% 置信水平的置信区间为', np.round(ci98,2))
98% 置信水平的置信区间为 [195.07 204.93]
ci96 =stats.norm.interval(confidence = 0.96, loc=sm, scale=ss)
print('96% 置信水平的置信区间为', np.round(ci96,2))
96% 置信水平的置信区间为 [195.64 204.36]
import numpy as np
sc= [34,36,36,38,38,39,39,40,40,41,41,41,41,42,42,45,49,56]
print('均值:', np.mean(sc), '\n中位数:', np.median(sc),
'\n方差:', np.var(sc).round(2), '\ns标准差:', np.std(sc).round(2))
均值:41.0
中位数:40.5
方差:24.11
s标准差:4.91
import warnings
warnings.filterwarnings("ignore")
sns.distplot(sc)
输出:
<Axes: ylabel='Density'>

sns.boxplot(sc)
输出:
<Axes: >

import pandas as pd
import numpy as np
dc3 = pd.read_csv('Cars.csv')
dc3.head()
输出:
Car | MPG | Cylinders | Displacement | Horsepower | Weight | Acceleration | Model | Origin | |
0 | Chevrolet Chevelle Malibu | 18.0 | 8 | 307.0 | 130 | 3504 | 12.0 | 70 | US |
1 | Buick Skylark 320 | 15.0 | 8 | 350.0 | 165 | 3693 | 11.5 | 70 | US |
2 | Plymouth Satellite | 18.0 | 8 | 318.0 | 150 | 3436 | 11.0 | 70 | US |
3 | AMC Rebel SST | 16.0 | 8 | 304.0 | 150 | 3433 | 12.0 | 70 | US |
4 | Ford Torino | 17.0 | 8 | 302.0 | 140 | 3449 | 10.5 | 70 | US |
m1= dc3['MPG'].mean()
s1= dc3['MPG'].std()
prob_mpg = (1 - stats.norm.cdf(38, loc= m1, scale= s1))
print('mpg > 38 的概率是', np.round(prob_mpg, 3))
mpg > 38 的概率是 0.038
prob_mpg2 = stats.norm.cdf(40, loc= m1, scale= s1)
print('mpg < 40 的概率是', np.round(prob_mpg2, 3))
mpg < 40 的概率是 0.978
prob_mpg3 = (1-stats.norm.cdf(20, loc= m1, scale= s1))
print('mpg > 20 的概率是', np.round(prob_mpg3, 3))
prob_mpg4 = stats.norm.cdf(50, loc= m1, scale= s1)
print('mpg < 50 的概率是', np.round(prob_mpg4, 3))
prob_mpg5= prob_mpg4 - prob_mpg3
print('mpg 在 20 到 50 之间的概率是', np.round(prob_mpg5, 3))
mpg > 20 的概率是 0.642
mpg < 50 的概率是 0.999
mpg 在 20 到 50 之间的概率是 0.358
import warnings
warnings.filterwarnings("ignore")
sns.distplot(dc3['MPG'])
输出:
<Axes: xlabel='MPG', ylabel='Density'>

# mean < median
dc3['MPG'].describe()
输出:
count 406.000000
mean 23.051232
std 8.401777
min 0.000000
25% 17.000000
50% 22.350000
75% 29.000000
max 46.600000
Name: MPG, dtype: float64
import pandas as pd
import numpy as np
db = pd.read_csv('wc-at.csv')
db.head()
输出:
Waist | AT | |
0 | 74.75 | 25.72 |
1 | 72.60 | 25.89 |
2 | 81.80 | 42.60 |
3 | 83.95 | 42.80 |
4 | 74.65 | 29.84 |
plt.figure(figsize= (18,8), dpi= 80)
plt.subplot(1,2,1)
sns.distplot(db['AT'])
plt.subplot(1,2,2)
sns.distplot(db['Waist'])
输出: