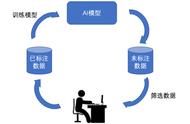
“算力、算法、数据”是推进人工智能应用的三大核心要素,人工智能的最终落地需要大量的数据进行训练,而数据标注便是形成高质量数据的最重要环节。目前,国内大模型的发展如火如荼,而数据标注作为大模型发展背后的推手却鲜有人关注。但随着细分领域垂类大模型的需求越来越多,专业领域大模型的数据需求向精细化、场景化发展,数据标注工作的专业化要求越来越高,亟需构建一套科学合理的数据标注工作体系。
那么,什么是数据标注?数据标注的类型、方法有哪些?数据标注目前面临哪些问题?本文将从这三个问题出发,浅谈数据标注实施路径。
01
什么是数据标注?
根据《人工智能训练师国家职业技能标准(2021年版)》、《生成式人工智能服务管理暂行办法》等政策法规,并结合业界通用定义,数据标注可理解为通过人工或自动化的方式,将原始数据转化为算法可理解的、结构化的数据集,通常是指对文本、图像、音频、视频等进行归类、整理、编辑、纠错、标记和批注等加工操作,构建模型要求且可读的数据编码。具体分类如下:
1.基于标注对象的数据标注类型划分
(1)图片标注
具体包括:
- 图像分类:识别一张图片中是否包含某种物体。
- 物体检测:识别出图片中每个物体的位置及类别。
- 图像分割:根据图片中的物体划分出不同区域。

(图像分割,取自EasyData平台)
(2)音频标注
具体包括:
- 声音分类:对声音进行分类。
- 语音内容:对语音的情感倾向等进行标注。
- 语音分割:对语音内容进行分段等。

(语音分割-取自ModelArts平台)
(3)文本标注
具体包括:
- 文本分类:对文本的内容按照标签进行分类处理。
- 命名实体:针对文本中的实体片段进行标注,如“时间”、“地点”等。
- 文本三元组:针对文本中的实体片段和实体之间的关系进行标注。
- 文本序列标注:针对文本质量进行排序。
- 多轮对话生成:多轮对话内容的生成、修改和批注。