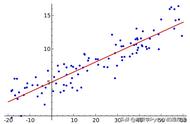
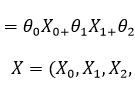从结果上来看模型的效果非常棒,和我们的预期非常吻合,并且实现的代码实在是太简单了,只有短短几行。
但实际上,有一点我必须要澄清,虽然上面的代码只有几行,非常方便,但是在实际使用线性回归的场景当中,我们并不会直接通过公式来计算θ,而是会使用其他的方法迭代来优化。
那么,我们为什么不直接计算,而要绕一圈用其他方法呢?
原因也很简单,第一个原因是我们计算θ的公式当中用到了逆矩阵的操作。在之前线性代数的文章当中我们曾经说过,只有满秩矩阵才有逆矩阵。如果 X^T·X 是奇异矩阵,那么它是没有逆矩阵的,自然这个公式也用不了了。
当然这个问题并不是不能解决的,X^T·X 是奇异矩阵的条件是矩阵X当中存在一行或者一列全为0。我们通过特征预处理,是可以避免这样的事情发生的。所以样本无法计算逆矩阵只是原因之一,并不是最关键的问题。
最关键的问题是复杂度,虽然我们看起来上面核心的代码只有一行,但实际上由于我们用到了逆矩阵的计算,它背后的开销非常大,X^T·X 的结果是一个n * n的矩阵,这里的n是特征的维度。这样一个矩阵计算逆矩阵的复杂度大概在 n^2.4 到 n^3 之间。随着我们使用特征的增加,整个过程的耗时以指数级增长,并且很多时候我们的样本数量也非常大,我们计算矩阵乘法也会有很大的开销。
正是因为以上这些原因,所以通常我们并不会使用直接通过公式计算的方法来求模型的参数。
那么问题来了,如果我们不通过公式直接计算,还有其他方法求解吗?
答案当然是有的,由于篇幅限制,我们放到下一篇文章当中。
今天的文章就到这里,如果觉得有所收获,请顺手点个关注或者转发吧,你们的支持是我最大的动力。