写在前面的话:码字不易,点个赞关注一下作者再走吧[呲牙]
================================================================
1.描述性统计方法(直观)1.直方图
由于正态分布具有非常典型的中间高,两边低的图形特征,如果样本数据并不服从正态分布,我们可以通过直方图很快地分辨出来。更进一步地,Python可以辅助生成基于样本数据估计的正态曲线,这样就容易辅助我们进行判断。
图形观察虽然直观,但是部分研究者认为单纯观察图形过于主观,因此我们也可以选择使用统计检验的方法去研究数据是否服从正态分布。
操作步骤:
导入相关的包及数据
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#用来显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
#导入数据
data = pd.read_excel('年龄_收入.xlsx')
#绘制年龄的频率直方图,20个箱体
plt.hist(data.年龄,bins = 20)
#绘制年龄带正态曲线的频率直方图
sns.distplot(data.年龄)
2 P-P图及Q-Q图
直方图是最长用于观察数据分布的常用图形选项,尤其是带正态曲线的直方图,可以非常直观地看到实际数据分布和正态曲线的对比,而P-P图及Q-Q图则是另一种选择,它可以直观给出实际数据分布和理论的差距。
值得注意的是,虽然P-P图及Q-Q图常用用于判断数据样本是否服从正态分布,但实际上它们也能判断数据样本是否服从其他的分布
P-P图:反映的是数据的实际累积概率与假定所服从分布的理论累积概率的符合程度。在此处,我们所假定的分布就是正态分布,如果数据样本是服从正态分布的话,那么实际的累积概率与理论的累积概率应该是相对一致的,放映在图形中就是数据点应该沿着图形的对角线分布。
Q-Q图的原理与P-P图几乎一致。P-P图考察的是实际分布与理论分布的累积概率分布差异,而Q-Q图考察的是实际百分位数与理论百分位数的差异。同理在此处,我们所假定的分布就是正态分布,如果数据样本是服从正态分布的话,那么实际的分布应该是相对一致的,反映在图形中就是数据点应该沿着图形的对角线分布。
在Python中,statsmodels包中目前主要提供的是Q-Q图的绘制
import statsmodels.api as sm
import pylab
sm.qqplot(data.年龄, line='s')
pylab.show()
sm.qqplot(data.收入, line='s')
pylab.show()
2.K-S检验
柯尔莫戈洛夫-斯米诺夫检验(Kolmogorov-Smirnov test),一般又称K-S检验,是一种基于累计分布函数的非参数检验,用以检验两个经验分布是否不同或一个经验分布与另一个理想分布是否不同。
K-S检验的原假设是“样本数据来自的分布与正态分布无显著差异”,因此一般来说,KS检验最终返回两个结果,分别是检验统计量及P值,检验结果P>0.05才是我们的目标。
from scipy.stats import kstest
#cdf中可以指定要检验的分布,norm表示我们需要检验的是正态分布
#常见的分布包括norm,logistic,expon,gumbel等
kstest(data.年龄,cdf = "norm")
实际上,GraphPad不推荐使用单纯的Kolmogorov-Smirnov test方法
3. W检验夏皮洛-威尔克检验(Shapiro—Wilk test),一般又称W检验。W检验是一种类似于利用秩进行相关性检验的方法。同样需要注意的是,W检验与K-S检验一样,原假设是“样本数据来自的分布与正态分布无显著差异”,因此一般来说,W检验最终返回两个结果,分别是检验统计量及P值。,检验结果P>0.05才是我们的目标。
当数据集中的数据无重复值时,该方法的检验效果比较好,但是当数据集中有些数据不是独一无二的,即有些数据的数值是相同的,那么该方法的检验效果就不是很好
from scipy.stats import shapiro
shapiro(data.年龄)
4.D'Agostino and Pearson omnibus normality test
GraphPad官方推荐使用该方法。
首先计算 偏度和峰度以便在不对称和形状方面量化分布离高斯分布的距离。然后,其计算这些值中的每一个与高斯分布的预期值之间的差异,并基于这些差异的总和,计算各P值。这是一种通用和强大的正态性检验,推荐使用。请注意,D'Agostino开发了几种正态性检验。Prism使用的其中一个是“综合K2”检验。
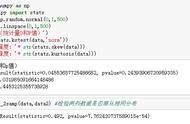
import scipy.stats
from scipy import stats
stats.normaltest(data)#normaltest中pvalue>0.05符合正态分布
5.安德森-达令检验(Anderson-Darling test)
安德森-达令检验样本数据是否来自特定分布,包括分布:'norm', 'expon', 'gumbel', 'extreme1' or 'logistic'.
原假设 H0:样本服从特定分布; 备择假设 H1:样本不服从特定分布
##用Anderson-Darling检验生成的数组是否服从正态分布
import scipy.stats as stats
stats.anderson(data_norm, dist='norm')
'''输出AndersonResult(statistic=0.18097695613924714,
critical_values=array([ 0.555, 0.632, 0.759, 0.885, 1.053]),
significance_level=array([ 15. , 10. , 5. , 2.5, 1. ]))
如果输出的统计量值statistic < critical_values,则表示在相应的significance_level下,
接受原假设,认为样本数据来自给定的正态分布。'''
实际上,从已有的文献表明,对于数据分布的正态性研究,首选方法是图形观察,即利用直方图、P-P图或Q-Q图进行观察,如果分布严重偏态和尖峰分布则建议进行进一步的假设检验。如果图形分布结果不好判断,则再进行正态性检验。
实际上,从已有的文献表明,对于数据分布的正态性研究,首选方法是图形观察,即利用直方图、P-P图或Q-Q图进行观察,如果分布严重偏态和尖峰分布则建议进行进一步的假设检验。如果图形分布结果不好判断,则再进行正态性检验。
其次,对于检验方法来说,对于K-S检验及W检验结果来说,有文献采用蒙特卡罗模拟方法进行多次验证,结果表明W检验结果相比于大部分方法都有较大的检验功效,而K-S方法的检验结果相对不佳。并且部分学者认为,K-S检验的实用性远不如图形工具,因为在样本量少时,该检验不太敏感,但是在样本量大时,该检验却过于敏感。因此正常情况下,我们更常采用W检验的结果。
值得注意的是,虽然说K-S检验结果相对不佳,但是不同检验方法对于样本量的敏感度是不一样的。在样本量较小的情况下(小于50个样本的情况下),请优先选择W检验;在样本量50-5000的情况下,可以酌情使用W检验及K—S检验;在样本量大于5000的情况下,请使用K-S检验结果,尤其是在SPSS中,当样本量大于5000的情况下,将只显示K-S检验结果,而不显示W检验结果。
,