因此,我们有理由相信任何一个流体工程师,都不会在如此强大的多核CPU上,使用串行方法来计算我们的Fluent仿真案例。因此,并行技术借助硬件的发展,已经成为流体仿真的必要(唯一)手段。

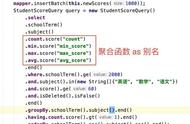
图4一些主流CPU的性能指标
3、算例更加精细,网格数量更多
硬件提升了,对应能够支持的网格数量也就随之增加,这也是近年来流体仿真取得突破性进展的坚实基础。如果时间倒退回十五年前,那么使用串行计算一个Fluent案例,将是一件非常正常的事情;但是对于眼下的仿真行业,已经无法再找到不使用并行计算的情况了。
Fluent仿真经过数十年的发展,很多行业已经不满足于使用相对粗糙的网格进行概略的求解,相反,更多的人希望各通过更加准确的几何细节,和更加精细的物理模型进行详细计算,从而得到更加完整、细致、精准的仿真结果。大规模的计算需要硬件的支持,也离不开并行技术的保障。
实际上,当流体仿真的网格数量超过10万时,并行计算的优势就已经可以很好的体现出来了,尤其是当一个核数对应5-8万个(六面体)体网格时,并行加速的效果是非常明显的。

图5 Fluent 使用13万核并行计算的超大规模燃烧问题加速比
4、Fluent中完美的并行技术
Fluent软件在并行的过程中,具备非常严谨的求解进程,既能充分调用已有的CPU资源,又能很好的保证计算结果的准确性,这是Fluent本身的优势,也是Fluent多年发展的成果。
可以豪不夸张的讲,Fluent具备有完美的并行能力,从任何一个角度来看都很难找到缺陷,这是其他有限元软件(至少在并行计算层面上)所无法企及的高度。因此,我们要更加珍惜Fluent的这一长处,更好的利用他,帮助我们完成仿真的任务。
值得一提的是,在Fluent R18.1之后的版本中,串行计算已经成为一个“遗留概念”;Fluent的求解架构已经完全按照并行的进程来开展工作了,即使我们选择了Serial(串行),Fluent仍旧会把算例当成1个核心的并行进行计算,从这个角度来讲,串行的UDF代码在18.1之后就退出了历史舞台,无论何种情况下,我们都必须使用并行UDF代码。

图6 串行问题在高版本的Fluent中仍旧按照并行架构进行求解
悄悄分享一个小秘密:18.1版本仍旧可以正确读取串行的UDF代码,但仅限紧急情况下使用。方法是:并行(Parallel)核数设置成0。
三、Fluent并行UDF代码中需要注意的问题首先需要明确的是,并行与串行的区别仅存在于代码之中,其他的UDF环节(如编译、解释、管理、与算例hook等)则不存在任何差别。因此,我们在已经具备的串行UDF技能基础之上,仅考虑以下四个方面的差异,即可满足并行需求:
1、并行专用的编译器指令
由于并行求解中需要区分主节点和子节点分别书写代码,因此必须要使用一些预处理的命令来判别使用的环境。当我们的代码中含有这一类指令时,读入主节点和子节点的代码会有很大的区别。