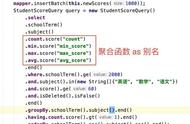
图7 并行专用的编译器指令
2、区分内部(internal)和外部(external)单元(cell)与面(face)的循环
并行计算必须首先对网格进行分区,这样才能提高整体的工作效率。分区结束后,通常在分区的交界处会出现一些特别的单元(cell)和面(face)。基于串行代码的循环宏在处理这一类分区交界单元(面)时可能会出现错误,但这些错误在串行问题中则不会发生,因此,必须要在并行UDF中对这一类单元(面)进行特殊的处理,从而避免循环过程中的错误。

图8 并行计算中分区的网格分类
3、全局变量(数据)缩减(变量一致性处理)
当多核并行计算时,一些全局变量(如平均速度等)在各个分区的网格中有不同的值,这就需要我们进行全局的数据统一。并行UDF在处理这一类问题中有专用的代码,可以较为轻松的实现全局变量(数据)的规模缩减和同步。
4、子节点与主节点之间的数据传输
根据并行仿真的架构,网格的变量数据并不包含在主节点中,通过TUI输入的值也不能直接被子节点获得,此时,就必须要通过代码来实现数据的传递,这样才能使代码中的一些功能得以有效实现