案例解析:仅从表格中新药组有效率70%,安慰组有效率50%,得出新药治疗该疾病的有效率大于安慰剂组的结论显然是不合理的。这可能是抽样带来的误差。我们基于一系列数据或者现象在得出结论之前,至少应该做一些统计推断,要知道抽样误差、P值、相对危险度、可信区间等等。
2
混杂因素控制思想
混杂因素:指的是除了研究因素外,其他所有可能会影响结局的因素(包括已知和未知的)。
混杂因素与结局事件、暴露/处理因素有关,但不是暴露/处理因素与结局事件的中间变量。例如:研究高血压与死亡风险之间的关系。糖尿病就可作为其混杂因素,糖尿病与高血压、死亡都可能有关,但不可以说高血压导致糖尿病从而引起死亡。

控制混杂因素的最大意义就是保证研究结果的真实性与可靠性,常用方法为:
①分层分析:最常见,一般只能针对一个混杂因素进行分析
②对因素分析:能够同时分析多个因素对结局的影响。最常使用的三种回归模型为:多重线性回归、logistic 回归及 Cox 回归。
③倾向性分析:用一个综合的分值来替代多个混杂因素,减少自变量个数,克服分层分析和多因素分析中对于自变量数量的限制。
【例2】英国某年原住民(因格兰和威尔士)和移民发病率统计资料:

案例解析:在原住民组中各个年龄分组的发病率均低于移民组,然而合计发病率却远高于移民组(辛普森悖论)。这个矛盾的结果可能就是存在非年龄因素(混杂因素)对研究产生了影响。这也提醒我们在一些观察性研究中,我们关心的研究因素很可能不是真正影响结果的因素。
3
多因素分析思想
单因素分析:是指在一个时间点上,研究不同水平的某因素对一个独立变量的影响程度的分析。即实验处理仅为一个方向,如研究不同药物对病例状态恢复的影响等。
多因素分析:是对一个独立变量是否受一个或多个因素或变量影响而进行的分析。
一般情况下,单因素和多因素分析相辅相成,单因素分析可以初步探索自变量与因变量的关系,并且当样本量不是很大的时候可以通过单因素分析删除部分无关的自变量;而多因素分析可以进一步排除其它混杂因素的影响,从而确定自变量与因变量的相关性。
将单因素和多因素的结果进行比较更容易发现问题,如果单因素和多因素结果一致,结论就比较稳定且容易解释,但在一些情况下出现结果矛盾时,千万不要觉得沮丧。这反而是你们大展身手的时候!想办法去解释矛盾之处,是一篇论文的亮点!
【例3】这是一篇1997年发表在《中华医院感染学杂志》的文章。这篇文章就是单因素分析代替多因素分析的错误案例。
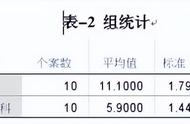
烧伤入我院治疗的132例患者中,有HCV感染者105例,占烧伤患者79.5%。对HCV感染者,我们进一步对年龄、有无输血及血制品、输血及血制品的量、烧伤程度等进行了对比分析(见表1、2、3)。
对HCV感染与诸因素相关性运用四格表专用公式法进行统计学处理,结果表明HCV感染与有无输血及血制品(χ2=12.05,P<0.01)、烧伤程度(χ2=5.03,P<0.05)有显著性差异,与输血及血制品的量(χ2=0.015,P>0.05)、年龄(χ2=0.0174,P>0.05)无明显差异。

表1. 不同年龄组输血及血制品与HCV感染