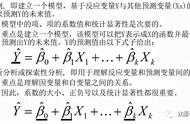作者丨GlobalTrack
编辑丨极市平台

论文链接:https://openreview.net/pdf?id=6kxApT2r2i
源码链接:https://github.com/yukimasano/single-img-extrapolating
简介本文研究关注于是否神经网络可以从单一数据训练并进行推断。
这个问题的主要难点在于:1. 当前深度学习优化的算法(SGD等)在大的数据集上设计的,不能在单一数据上推广,2. 需要关于单个数据之外的自然图像空间信息的语义类别进行推断。本文的主要思想是结合数据增广和知识蒸馏的相关算法。
数据增广算法可以通过单一图像生成大量变化,有效解决一般优化方法只在大型数据集上设计难以优化的问题1。为了解决单一数据设定难以提供语义类别相关信息的问题,本文方法选择使用有监督训练模型的输出和知识蒸馏算法。使用知识蒸馏算法提供训练过程中需要的语义类别信息。
相关工作知识蒸馏一般的知识蒸馏主要目标即使用一个预训练的教师模型信息辅助训练一个低学习能力的学生模型。利用教师模型获得的软预测结果获得类别间关系提升学生模型训练性能。早期方法只使用最终层输出,其他转移的特征还包括:中间层特征;空间注意力后特征,对比学习蒸馏等。
无数据知识蒸馏无数据知识蒸馏(Data-Free Knowledge Distillation)一般用于极端巨大数据集,有隐私需求的数据集或只能获得API模型输出的需求等。原始方法一般需要训练数据集相关激活层统计信息。之后提出的方法一般不需要此类信息。使用基于生成的方法生成合成图像数据集,最大限度地激活教师最后一层的神经元。
本文方法数据生成在A critical analysis of self-supervision, or what we can learn from a single image研究中,一个单一的图片增广若干次生成一个固定尺寸的静态数据集。增广方法包括切割,旋转,剪切和颜色抖动( cropping, rotation,shearing,color jittering)。本文也使用相同的方法并不改变超参。这里通过添加随机噪声分析源图像选择。另外本文实验也关注了音频分类。这里选择的赠官该方法包括随机音量增加,背景噪声添加和变桨(pitch shifting)。
知识蒸馏原始知识蒸馏算法(Distilling the knowledge in a neural network)将一个预训练的教师模型的知识迁移到一个能力较弱的学生模型。学生模型的优化目标是一个两种损失函数的加权组合:一个标准的交叉熵损失和分布匹配损失(减少与教师模型结果的分布差异)。
本文方法特殊的是对于生成的单一图像没有标签信息,这里使用学生模型结果与教师模型结果的KL散度信息:

训练时按照Knowledge distillation: A good teacher is patient and consistent的功能匹配策略,教师与学生模型传入一致的增广示例。复杂增广的方法包括MixUp和CutMix。
实验这里检查从单一图像推断到小尺寸数据集的能力。表1给出了在CIFAR10和CIFAR100数据集上的实验结果。使用源数据集在源数据集达到最高的精度,但使用单个图像得到的模型也可以达到下界。另外单一图像蒸馏甚至超过了使用CIFAR-10的10K图像指导CIFAR-100训练即使两个数据集相似。

单一图像的选择 这里发现单一图像选择是重要的。随机噪声或稀疏的图像与密集标签bridge和Animal图像性能差很多。
损失函数的选择 图3(b)发现本文方法的学生模型甚至能从下降质量的学习信号下学习。即使受到的是TOP-5的预测或者最大预测(硬标签),学生模型也能在很大意义上进行推断(>91%/60%)。
增广策略选择 图3(c)给出了不同的增广策略,除了之前指出的策略:更多的增广更好。本文发现在本文的单一图像蒸馏任务上CutMix比MixUp性能更好。