也可以在病毒入侵前就拦截,同样需要获知各种结构以及探索相互作用
这个过程中,需要大量病毒自身以及我们细胞内的蛋白以供研究,比如解析结构,探索相互作用等,那么这些蛋白如何获取呢?
两条路一是天然蛋白,二是*蛋白。
对于天然蛋白,字面意思,想办法直接从病毒中分离并提纯我们所需的蛋白。
首先,这种病原体不是随便找个实验室就有操作资格,搞不好就是生化危机。另外,在具体实验中,由于分离纯化工艺繁琐、产率低和成本高等缺陷,除了个别场合,这个方法基本已脱离实验室研究。

实验室中常用的是*蛋白,比如上面的合成人胰岛素、最近解析新冠病毒S蛋白的几项研究中使用的都是这类。
*蛋白的产生是应用了*DNA或*RNA的技术从而获得的蛋白质,说白了就是转基因技术的产物。这种蛋白的生产主要分为以下几步:

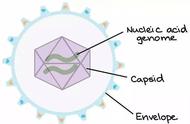
很关键的一张图,建议保存或者收藏
步骤- 目标基因的获取
蛋白质是靠生化反应合成的,而指导到底合成哪种蛋白的是DNA和RNA。考虑到“转”基因一般转的都是DNA,在明确需要哪种蛋白后,我们首先应该获得这种蛋白对应的DNA序列,此处称其为目标基因。

如果不记得DNA、RNA和蛋白质的关系建议先查一下
有两种思路:一是分离,二是合成。
分离是指直接从新冠病毒中分离RNA序列,然后逆转录成DNA。这个过程也是因为比较麻烦,获取产物纯度可能不理想,所以应用场合很受限。比如我们发现一种新病毒,不知道具体DNA或RNA序列,只能先纯化然后测序。