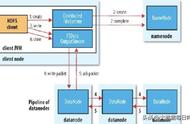
▲图3-3 流水线数据写入示意图
3)串行写入数据,直到写完Block
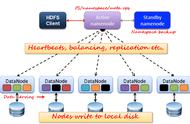
客户端的数据以字节(byte)流的形式写入chunk(以chunk为单位计算checksum(校验和))。若干个chunk组成packet,数据以packet的形式从客户端发送到第一个Datanode,再由第一个Datanode发送数据到第二个Datanode并完成本地写入,以此类推,直到最后一个Datanode写入本地成功,可以从缓存中移除数据包(packet),如图3-4所示。

▲图3-4 串行写入数据示意图
4)重复步骤2和步骤3,然后写数据包和回复数据包,直到数据全部写完。
5)关闭文件并释放租约
客户端执行关闭文件后,HDFS客户端将会在缓存中的数据被发送完成后远程调用Namenode执行文件来关闭操作。
Datanode在定期的心跳上报中,以增量的信息汇报最新完成写入的Block,Namenode则会更新相应的数据块映射以及在新增Block或关闭文件时根据Block映射副本信息判断数据是否可视为完全持久化(满足最小备份因子)。
2. HDFS客户端读流程
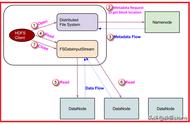
相对于HDFS文件写入流程,HDFS读流程相对简单,如图3-5所示。

▲图3-5 HDFS读流程
1)HDFS客户端远程调用Namenode,查询元数据信息,获得这个文件的数据块位置列表,返回封装DFSIntputStream的HdfsDataInputStream输入流对象。
2)客户端选择一台可用Datanode服务器,请求建立输入流。
3)Datanode向输入流中写原始数据和以packet为单位的checksum。
4)客户端接收数据。如遇到异常,跳转至步骤2,直到数据全部读出,而后客户端关闭输入流。当客户端读取时,可能遇到Datanode或Block异常,导致当前读取失败。正由于HDFS的多副本保证,DFSIntputStream将会切换至下一个Datanode进行读取。与HDFS写入类似,通过checksum来保证读取数据的完整性和准确性。
本文摘编自《腾讯大数据构建之道》,经出版方授权发布。(ISBN:978-7-111-71076-9)

延伸阅读《腾讯大数据构建之道》
推荐语:腾讯官方出品!腾讯大数据构建之道首次对外披露!腾讯大数据平台十年磨一剑,践行“科技向善”落地方案。本书由腾讯数据平台部组织,腾讯公司副总裁蒋杰领衔撰写,首次对外详细阐述了腾讯大数据平台系统架构,以及多年来平台建设的思考与沉淀。
关于作者:核心团队,腾讯数据平台部致力于为腾讯集团旗下业务提供专业、可靠的大数据平台及机器学习平台服务,并依托腾讯云将大数据与AI能力对外输出。团队专注于大数据、云原生、机器学习、图计算、AI视觉和推荐技术等核心技术,并在world-Class比赛中屡获奖项。同时,团队全面拥抱开源并持续贡献社区,自主研发的分布式机器学习平台Angel和大数据集成平台InLong分别从Linux和Apache顶级项目毕业,具有world-Class的技术影响力。
核心作者,蒋杰,北京大学博士,腾讯公司副总裁,中国人工智能产业发展联盟(AIIA)副理事长,中国计算机学会(CCF)大数据专家委员会委员。