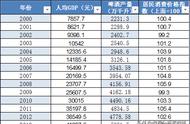
你可以看到,对于所有的变量,季节性因素看起来都很混乱。这是因为我们分析的是每小时的数据,这些季节变化是在一天内观察到的,并没有直接的关联。所以我们可以尝试将数据重新采样到每日间隔,并在一天的时间段内进行分解。
df_d = df.resample('1d').mean()

请注意到图表右上角的Dickey-Fuller(ADF) 。这是一个平稳性测试,使用的是adfuller函数。对于时间序列,平稳性意味着时间序列的属性不随时间变化。我们这里说的属性是指:方差、季节性、趋势和自相关性。
Dickey-Fuller (ADF)检验的流程是:提出时间序列是非平稳的零假设。然后我们选择显著性水平α,通常为5%。α是错误地拒绝零假设的概率,而零假设实际上是正确的。所以在我们的例子中,α=5%有5%的风险得出时间序列是平稳的,而实际上不是。
测试结果会给出一个p值。如果小于0.05,我们可以拒绝零假设。可以看到,根据ADF检验所有4个变量都是平稳的。
一般情况下要应用时间序列预测模型,如ARIMA等,平稳性是必须的。这也是我们选择气象数据的原因,因为它们在大多数情况下是平稳的,所以才会出现在不同的时间序列相关的学习材料中进行分析。
分布在得出所有时间序列都是平稳的结论之后,让我们来看看它们是如何分布的。我们将使用著名的seaborn库及其函数pairplot,该函数允许使用历史和kde创建信息丰富的图。
ax = sns.pairplot(df, diag_kind='kde')
ax.map_upper(sns.histplot, bins=20)
ax.map_lower(sns.kdeplot, levels=5, color='.1')
plt.show()

让我们考虑t2m(1行1列)的示例。在分析核密度估计(kde)图时,很明显这个变量的分布是多模态的,这意味着它由2个或更多的“钟形”组成。在本文的后续阶段中,我们将尝试将变量转换为类似于正态分布的形式。
第一列和第一行中的其他图是相同的,但它们的可视化方式不同。这些是散点图,可以确定两个变量是如何相关的。所以一个点的颜色越深,或者离中心圆越近,这个区域内点的密度就越高。
Box-Cox转换由于我们已经发现气温时间序列是平稳的,但不是正态分布,所以可以尝试使用Box-Cox变换来修复它。这里使用scipy包及其函数boxcox。
df_d['t2m_box'], _ = stats.boxcox(df_d.t2m)
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(15,7))
sns.histplot(df_d.t2m_box, kde=True, ax=ax[0])
sns.histplot(df_d.t2m, kde=True, ax=ax[1])