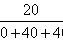5.2 多次测试
简单的说:传统的假设检验的设置是对需要检测的「假设」进行唯一测试,然后计算 p 值。我们有 5% 的概率观测到某一个并没有实际变化的“指标”显得有统计意义上的显著变化。
现实中,对于同一个实验,我们通过 AB 实验反复观察结果,或者反复针对同一个想法进行迭代。
出现更严重的问题就是:我们针对同一个实验,常常同时观测几十个或者上百个指标,导致出现多次实验的问题,大大增加了观测并不该有显著变化的指标有了统计意义变化的概率。
5.3 方差的计算
t检测中我们需要对数据的方法进行计算。有时候我们的“方差”计算是有问题的,之前有说到的「随机单元」和「分析单元」不一致的情况下,计算比率型的指标,比如点击率。
我们来看一个场景:经常我们的「随机单元」是用户级别的,然而我们希望计算的是一些页面级别的点击率,然后看对照组和实验组之间的差别的,这个时候就存在「随机单元」和「分析单元」不一致的问题,传统的计算点击率的「方差」公式可能存在问题。
5.4 样本比率偏差
在理想的状态下,对照组和实验组的流量是一半一半的,也就是 50% 的进入到对照组,50% 的进入到实验组。但是现实是残酷的,比如会出现 50.27% 的用户进入到对照组,另外 49.73% 的用户进入到实验组。
这种情况正常吗?我们还信任这样的实验结果吗?
这样情况的排查和分析。简单的说,我们需要把这样的分流结果当作假设检验,看这样的结果是否异常。
5.5 AA 实验
AA 实验往往作为检测平台稳定性和实验设置是否正确的重要手段。
总是有人想着做「AA」实验,为什么会这样呢?说到底还是对于 AB 实验存在疑虑和不信赖。大多数想做 AA 实验的目的主要是:验证用户分流是否“均匀”;比较“ AA 组内差异”和“ AB 组间差异”。
其实 AA 实验中的指标差异显著/置信并不代表分流不科学,AA 实验的指标必然存在差异,并且指标差异可能还不小,AA 差异可能“显著”。
也就是说,对 AB 系统本身进行测试,以确保系统在 95% 的时间内正确识别出没有统计学意义上的显著差异。
5.6 对照组和实验组之间干涉
传统的实验我们假设对照组和实验组是完全隔绝的,然后实际中,完全的隔离是不可能的。
举个例子:
社招网络中,朋友与朋友的关系,我们按照传统的随机划分流量的方法,可能一个用户在对照组,他的朋友在实验组,这样这个用户可能接触到对照组的一些信息,从而违背了假设检验的一系列基本假设。
5.7 指标的长期效果
有一些“指标”的效果在 A/B 实验之后,可能会出现一些“恶化”,也就是说,效果可能没有之前那么明显了,甚至会出现效果完全消失。
如果遇到短期效果与长期效果可能出现不一致的情况,建议延长测试时间,观察长期效果。
但是长期存在一些问题:
(1)用户唯一标识(比如:ssid)跳变的情况,进行实验时候,通过随机分配的 ssid,进行确定用户身份,但是用户可以在浏览器中修改 localstorage 中的 ssid,保持一个稳定的样本几乎不可能,实验进行的越久,问题越严重。
(2)幸存者偏差的情况,过度关注幸存者,忽略没有幸存的而造成错误结论。
(3)选择偏差的情况,由于 ssid 跳变,只有登陆的用户组成,不具备代表性。
6. 总结
- https://www.cambridge.org/core/books/trustworthy-online-controlled-experiments/D97B26382EB0EB2DC2019A7A7B518F59
- https://stats.stackexchange.com/a/354377/320904
欢迎加入字节跳动数据平台团队
我们以赋能字节跳动各业务线,降低数据应用的门槛为始,以建立数据驱动的智能化企业,赋能各行业的数字化转型,创造更大的社会价值为终。当前我们处在的阶段是,对内支持了字节绝大多数业务线,已成为公司数据驱动的基石,每天有几万员工在使用我们的数据能力和数据内容,对外发布了火山引擎品牌下的数据智能产品,服务了各行业的客户。
通过下方链接进行简历投递,加入我们,让我们一起做「数据驱动」的领军者!
北京/上海/深圳/杭州/南京/海外多地职位开放:https://job.toutiao.com/s/MvCf2cJ