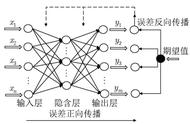
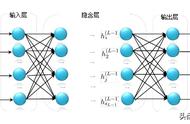
以上就是JAVA写的BP神经网络拟合曲线Y=n*2 23的程序。我们看看拟合结果吧:

BP神经逼近函数Y=n*2 23
第一列为理想输出值(函数Y=n*2 23,n从0到19),第二列为训练完后BP神经网络计算逼近输出值,第三列为误差性能指标(方差和)。可以观察到第一列和第二列的值非常接近,说明神经网络训练逼近模型还是很成功的。最后我们还测试了n=30时,BP神经网络模具输出值,也很理想接近83.0(我们只训练了n从0到19的数据)。
可见经过多次(通常上万次)权值修正函数(美工刀)的微调,神经网络结构(万能模具)已几乎具有函数Y=n*2 23的功能。
好了,见识了神经网络结构的巨大潜力,来细究它的一些局限和注意事项吧:
输入样本归一化的重要性:
1.避免数值过大问题:若不进行归一化处理,所得的输出,权值等往往会很大,而偏差也就很大,而权值调节中需要偏差*权值*输入,及偏差的积分和,这得到的数值将会很大,超出了数量级,也就超出了计算机等处理器的数值范围(我开始就是这样,导致偏差积分根本不能求),权值修正很差。
2.归一化将有单位的量纲转换成无量纲的了,便于BP网络的计算。
3.使网络快速的收敛。
尽量的使尽可能多的输入样本归一化,不完全归一化也能实现效果。
归一化方法:
(测量值—最低标度)/(最大标度—最低标度)等(就是求占得百分比)
可能陷入局部最优解:
前面针对反向学习算法的二次性能修正函数已经做过介绍,表现出来最明显的现象就是,在神经网络训练过程中,由于初始化权值的随机,可能一开始就走偏了,一直无法满足偏差最小情况。学习时间很长还没有出结果,可能就是陷入了局部凹坑。需要重新初始化BP神经网络。
它就是个黑盒子:
神经网络是经过不断的训练数据,不断的调整连接权值。就像是在不断的总结经验,给它一系列输入,对应得到一系列输出。一直在模仿,就如熟能生巧样,仿佛它自己找到了事物的规律。就如中医一样,有很多前人的经验,有些确实有很好的疗效,甚至凭多年的经验,自己能够抓药配药。但一直没有强有力的科学理论依据,所以充满未知(细思极恐),稳定性也得不到保证。
对数据要求较高:
计算机只能处理计算机语言,所以需要处理现实中的问题,就需要转换为计算机能处理的数据,图片就需要转换为二进制编码,但二进制编码也包含了广泛的内容(颜色编码,方位编码,明亮编码),如瓶子装水一般,有清水、污水、酸性、碱性等性质不同。当你训练神经网络时用的是什么特征的数据,那么测试时就也该在这个特征范围内。(装清水的瓶就该只装清水)
拿Google识别图片来说,训练时是未经处理的图片,直接将图片的二进制存储信息等交由计算机处理就行。而如果人为的加入干扰,人眼直接可辨识出物体名称,而Google识图却出错了(如今已修复大部分问题)。具体操作可参考以下网页内容:
阿里的数字水印
http://blog.jobbole.com/105968/
在图片中加入噪点就能骗过 Google 最顶尖的图像识别 AI
http://www.oschina.net/news/84329/noise-can-fool-google-ai
以上,是我学习BP神经网络中的一些总结,能力有限难免有纰漏之处。