机器之心报道
编辑:蛋酱
在这篇新论文中,TOELT LLC 联合创始人兼首席 AI 科学家 Umberto Michelucci 对自编码器进行了全面、深入的介绍。

论文链接:https://arxiv.org/pdf/2201.03898.pdf
神经网络通常用于监督环境。这意味着对于每个训练观测值 x_i,都将有一个标签或期望值 y_i。在训练过程中,神经网络模型将学习输入数据和期望标签之间的关系。
现在,假设只有未标记的观测数据,这意味着只有由 i = 1,... ,M 的 M 观测数据组成的训练数据集 S_T。

在这一数据集中,x_i ∈ R^n,n ∈ N。
1986 年,Rumelhart、Hinton 和 Williams 首次提出了自编码器(Autoencoder),旨在学习以尽可能低的误差重建输入观测值 x_i。
为什么要学习重建输入观测值?
如果你很难想象这意味着什么,想象一下由图片组成的数据集。自编码器是一个让输出图像尽可能类似输入之一的算法。也许你会感到困惑,似乎没有理由这样做。为了更好地理解为什么自编码器是有用的,我们需要一个更加翔实(虽然还没有明确)的定义。

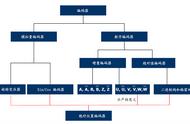
图 1:自动编码器的一般架构。
为了更好地理解自编码器,我们需要了解它的经典架构。如下图 1 所示。自编码器的主要组成部分有三个:编码器、潜在特征表示和解码器。