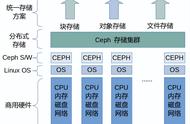
ceph_pool_pg
说明:
- pool是ceph存储数据时的逻辑分区,它起到namespace的作用。
- 每个pool包含一定数量(可配置)的PG。
- PG里的对象被映射到不同的Object上。
- pool是分布到整个集群的。
- pool可以做故障隔离域,根据不同的用户场景不一进行隔离。
2.8 Ceph 数据扩容PG分布
场景数据迁移流程:
- 现状3个OSD, 4个PG
- 扩容到4个OSD, 4个PG
现状:

ceph_recory_1
扩容后:

ceph_io_recry2
说明
每个OSD上分布很多PG, 并且每个PG会自动散落在不同的OSD上。如果扩容那么相应的PG会进行迁移到新的OSD上,保证PG数量的均衡。
3. Ceph心跳机制
3.1 心跳介绍
心跳是用于节点间检测对方是否故障的,以便及时发现故障节点进入相应的故障处理流程。
问题:
- 故障检测时间和心跳报文带来的负载之间做权衡。
- 心跳频率太高则过多的心跳报文会影响系统性能。
- 心跳频率过低则会延长发现故障节点的时间,从而影响系统的可用性。
故障检测策略应该能够做到:
- 及时:节点发生异常如宕机或网络中断时,集群可以在可接受的时间范围内感知。
- 适当的压力:包括对节点的压力,和对网络的压力。
- 容忍网络抖动:网络偶尔延迟。
- 扩散机制:节点存活状态改变导致的元信息变化需要通过某种机制扩散到整个集群。
3.2 Ceph 心跳检测

ceph_heartbeat_1
OSD节点会监听public、cluster、front和back四个端口
- public端口:监听来自Monitor和Client的连接。
- cluster端口:监听来自OSD Peer的连接。
- front端口:供客户端连接集群使用的网卡, 这里临时给集群内部之间进行心跳。
- back端口:供客集群内部使用的网卡。集群内部之间进行心跳。
- hbclient:发送ping心跳的messenger。
3.3 Ceph OSD之间相互心跳检测