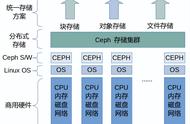
ceph_heartbeat_osd
步骤:
- 同一个PG内OSD互相心跳,他们互相发送PING/PONG信息。
- 每隔6s检测一次(实际会在这个基础上加一个随机时间来避免峰值)。
- 20s没有检测到心跳回复,加入failure队列。
3.4 Ceph OSD与Mon心跳检测

ceph_heartbeat_mon
OSD报告给Monitor:
- OSD有事件发生时(比如故障、PG变更)。
- 自身启动5秒内。
- OSD周期性的上报给Monito
- OSD检查failure_queue中的伙伴OSD失败信息。
- 向Monitor发送失效报告,并将失败信息加入failure_pending队列,然后将其从failure_queue移除。
- 收到来自failure_queue或者failure_pending中的OSD的心跳时,将其从两个队列中移除,并告知Monitor取消之前的失效报告。
- 当发生与Monitor网络重连时,会将failure_pending中的错误报告加回到failure_queue中,并再次发送给Monitor。
- Monitor统计下线OSD
- Monitor收集来自OSD的伙伴失效报告。
- 当错误报告指向的OSD失效超过一定阈值,且有足够多的OSD报告其失效时,将该OSD下线。
3.5 Ceph心跳检测总结
Ceph通过伙伴OSD汇报失效节点和Monitor统计来自OSD的心跳两种方式判定OSD节点失效。
- 及时:伙伴OSD可以在秒级发现节点失效并汇报Monitor,并在几分钟内由Monitor将失效OSD下线。
- 适当的压力:由于有伙伴OSD汇报机制,Monitor与OSD之间的心跳统计更像是一种保险措施,因此OSD向Monitor发送心跳的间隔可以长达600秒,Monitor的检测阈值也可以长达900秒。Ceph实际上是将故障检测过程中中心节点的压力分散到所有的OSD上,以此提高中心节点Monitor的可靠性,进而提高整个集群的可扩展性。
- 容忍网络抖动:Monitor收到OSD对其伙伴OSD的汇报后,并没有马上将目标OSD下线,而是周期性的等待几个条件:
- 目标OSD的失效时间大于通过固定量osd_heartbeat_grace和历史网络条件动态确定的阈值。
- 来自不同主机的汇报达到mon_osd_min_down_reporters。
- 满足前两个条件前失效汇报没有被源OSD取消。
- 扩散:作为中心节点的Monitor并没有在更新OSDMap后尝试广播通知所有的OSD和Client,而是惰性的等待OSD和Client来获取。以此来减少Monitor压力并简化交互逻辑。
4. Ceph通信框架
4.1 Ceph通信框架种类介绍
网络通信框架三种不同的实现方式:
- Simple线程模式
- 特点:每一个网络链接,都会创建两个线程,一个用于接收,一个用于发送。
- 缺点:大量的链接会产生大量的线程,会消耗CPU资源,影响性能。
- Async事件的I/O多路复用模式
- 特点:这种是目前网络通信中广泛采用的方式。k版默认已经使用Asnyc了。
- XIO方式使用了开源的网络通信库accelio来实现
- 特点:这种方式需要依赖第三方的库accelio稳定性,目前处于试验阶段。
4.2 Ceph通信框架设计模式
设计模式(Subscribe/Publish):
订阅发布模式又名观察者模式,它意图是“定义对象间的一种一对多的依赖关系,
当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新”。
4.3 Ceph通信框架流程图

ceph_message
步骤:
- Accepter监听peer的请求, 调用 SimpleMessenger::add_accept_pipe() 创建新的 Pipe 到 SimpleMessenger::pipes 来处理该请求。
- Pipe用于消息的读取和发送。该类主要有两个组件,Pipe::Reader,Pipe::Writer用来处理消息读取和发送。
- Messenger作为消息的发布者, 各个 Dispatcher 子类作为消息的订阅者, Messenger 收到消息之后, 通过 Pipe 读取消息,然后转给 Dispatcher 处理。
- Dispatcher是订阅者的基类,具体的订阅后端继承该类,初始化的时候通过 Messenger::add_dispatcher_tail/head 注册到 Messenger::dispatchers. 收到消息后,通知该类处理。
- DispatchQueue该类用来缓存收到的消息, 然后唤醒 DispatchQueue::dispatch_thread 线程找到后端的 Dispatch 处理消息。

ceph_message_2
4.4 Ceph通信框架类图