添加第二个项目
好了我们现在添加了两个操作,接下来我们要用这个url去获取URL内容,嗯好的找到“获取URL内容”操作添加它,通常添加完毕它已经自动选上了我们前面定义的url操作,这样就关联起来了,这个操作是重点,我们有很多的参数要配置

展开参数
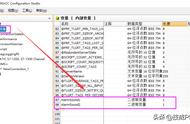
点击小箭头我们展开参数首先呢要把方法改成POST,然后呢我们展示一张配置完成的图你们看看

需要配置的所有参数
下面对参数做一些详细的介绍
方法 POST
头部 Content-Type application/json
Authorization Bearer 你的apikey 填这里
请求体 model text-davinci-003
prompt 参数选你前面的文本听写操作
max_tokens 500
top_p 1
frequency_penalty 0
presence_penalty 1
temperature 1
上边列出了具体的参数,你们对着图来填就行了,不需要加引号,请求体里面这些参数是openai的要求参数
Content-Type是请求的数据内容类型
Authorization 这个是重点我们openai里面创建的apikey就通过这个参数传给api作为访问授权,Bearer空格后面跟ApiKey,ApiKey在openai账号里是免费创建的创建方法自行百度了,百度有的我就不说了,很简单的,你们有什么搞不定的在评论区里问。
model是模型名称这里填的是达芬奇003,是api里最牛的,据说chatgpt的测试模型也在api里神出鬼没但是因为不稳定先不管他,等他稳定发布以后你可以填上chatgpt的模型名称,
prompt呢是你的提问文本,这里我们要指向前面的听写操作结果,
max_tokens呢是最大返回结果数,你可以理解为返回多少单词就好,达芬奇我记得最大是可以放到2048个token的,你只要不超过这个数都可以,理论上500可以省点费用万一结果不是你想要的那么就此打住,openai的api是按token来计费的,如果你们是免费换号玩家当我没说,按最大的整。
top_p ,frequency_penalty ,presence_penalty ,temperature 这几个值你们自己去查吧我就不在这里扯了对我们今天的实现影响不大,而且本来他们有的应该要填小数的操作输入的数字只能填整数我就都填1了,这些细节你们慢慢了解慢慢优化吧,我就不啰嗦了,我们继续
在完成这个内容请求操作之后我们就要对结果进行处理了,通常请求之后返回的是一个json,但是这个json返回体里面的很多东西我们都不想要,所以我就通过两个字典取值操作来获取最终结果,你们跟着我的步骤来就行了,首先添加一个获取词典的操作从我们刚才的url内容中获取词典,这个词典其实就是返回的json数据

添加获取词典操作
大家按照图中的来哈,搞不定的自己琢磨一下,或者在评论区交流一下,获得了这个词典以后我们再添加那两个取值的操作获得我们最终的请求返回文字文本,过程就不细说了就是添加操作以上一次的结果作为下一次的参数