李岩在演讲中表示,多模态技术有两大应用方向,一是会改变人机交互的方式,二是将使信息分发更加高效;视频本身就是一个多模态的问题,而快手则拥有海量的多模态数据,多模态的研究对于快手来说是非常重要的课题;目前快手已经在语音识别与合成、智能视频配乐、通过2D图像驱动3D建模特效、视频精准理解等领域对多模态技术进行研发应用。

以下为演讲的主要内容:
大家好,首先我来简单介绍一下快手,在这个平台,用户能够被广阔的世界看到,也能够看到广阔的世界,我们可以看一下快手的数据: 70亿条视频总量、1500万日新增视频,日均的使用时长超过60分钟等,所以快手平台上有非常多的多媒体数据,同时也有非常多的用户交互数据,比如我们每天有1.3亿用户观看超过150亿次视频的播放数据。
我们知道视频是视觉、听觉、文本多种模态综合的信息形式,而用户的行为也是另外一种模态的数据,所以视频本身就是一个多模态的问题,再加上用户行为就更是一种更加复杂的多模态问题。所以多模态的研究对于快手来说,是非常重要的课题。
多模态技术两大应用方向:人机交互与信息分发
我认为多模态技术会有两大主要的应用。
第一,多模态技术会改变人机交互的方式,我们与机器交互的方式将会越来越贴近于更令人舒适、更自然的方式。
第二,多模态技术会使得信息的分发更加高效。

多模态技术研究的三个难点:语义鸿沟、异构鸿沟、数据缺失
其实在目前来看,多模态研究难度还是非常高的。
其中大家谈得比较多的是语义鸿沟,虽然近十年来深度学习和大算力、大数据快速发展,计算机视觉包括语音识别等技术都取得了非常大的进展,但是截至现在,很多问题还没有得到特别好的解决,所以单模态的语义鸿沟仍然是存在的。
再者,由于引入了多种模态的信息,所以怎样对不同模态之间的数据进行综合建模,会是一个异构鸿沟的问题。
另外,做语音、做图像是有很多数据集的,大家可以利用这些数据集进行刷分、交流自己算法的研究成果。但是多模态的数据集是非常难以构建的,所以我们在做多模态研究时是存在数据缺失的问题的。
下面我会分享我们在多模态这个方面所做的事情,以及这些技术是怎么样帮助快手平台获得更好的用户体验和反馈的。
多模态技术如何实现更好的记录
首先,多模态技术将实现更好的记录。随着智能手机的出现,每个人都可以用手机上摄像头去记录周围的世界,用麦克风去存储周围的音频信息;而在以前,生成视频,尤其生成一些比较专业的视频,都是导演*事情。但现在,我们通过手机就能够做到,这里面会有非常多的多模态技术研究来辅助人们更好地记录。
我们希望整个记录过程是更加便捷、个性化、有趣,同时也是普惠的,具体我将分别通过四个案例分享。
1、语音转文字打造便捷字幕生成体验
一个视频里,音频部分对于整个视频的信息传递是非常重要的。网上有很多带有大量字幕的、以讲述为主的视频,这样的视频制作其实是一件很麻烦的事情,因为一个一个去输入文字是很痛苦的,像过去在广电系统专业工作室就需要很多用于字幕编辑的工具软件。而如果我们通过语音识别技术,把语音直接转成文字,就可以很轻松地通过手机编辑生成一个带字幕视频。
2、语音合成实现个性化配音
另外一个技术叫做个性化配音,假如在一个视频中,你不喜欢听男性配音,而希望听到由一位女士配音,我们就可以通过语音合成技术满足个性化的诉求。
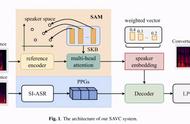
语音识别及合成技术都会使我们记录的过程变得更加便捷、有趣,但这两个技术在做视觉或者多媒体的圈子里面关注度不是特别高,只是偶尔会在做语音的圈子里去聊这些问题。包括在语音圈子里面,语音识别和合成现在往往是两波人在做。

随着深度学习技术的出现,语音识别和合成这两个问题其实在某种程度上是非常对称的,因为语音识别是从语音到文字,语音合成是从文字到语音。语音识别的时候,我们提取一些声学的特征,经过编码器或者Attention的机制,实现从语音到文字的转化;语音合成的技术和算法,其实也涉及编码器或者Attention的机制,二者形成了比较对称的网络。所以我们把语音识别和合成看成是一个模态转换的特例,从神经网络建模角度来看,是一个比较一致、容易解决的问题。