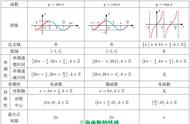
具体神经网络在设计的时候,虽然二者内容机制其实还是有一些不同,但更大的趋势是这里面将来会有更多的趋同,因为我们知道随着相关算法的发展,计算一定是朝着一个更加简化,更加统一的方向发展。就像深度学习的出现,其实就是通过计算的方式取代了手工来获取有效的特征。多模态的转换领域里面也出现了这样的特点,这是一件非常有意思的事情。
3、根据视频内容自动生成音乐
音乐也是短视频非常重要的一部分,有录视频经验的同学可以感受到,为一个场景配合适的音乐是一个很难的事情。过去,有不少用户为了与音乐节拍一致,努力配合音乐节奏拍摄,极大限制了拍摄的自由度。我们希望用户可以随意按照自己想要的节奏录制,所以让机器通过用户拍摄的视频内容,自动生成符合视频节奏的音乐,这样视频画面与音乐节奏就会更匹配、更一致。

音乐生成涉及很多具体的技术,我们也做了非常多的研究,其中一个问题是懂音乐的不懂计算机科学,懂计算机科学的人不懂音乐。想要把短视频配乐这个问题研究好,需要要有做音乐和做AI的人一起集成创新,这方面我们也做了非常多的工作。
4、2D图像驱动3D建模实现Animoji效果
通过苹果的发布会,大家应该都了解Animoji这项技术,iphoneX有一个标志性的功能,就是通过结构光摄像头实现 Animoji,现在国内手机厂商也越来越多地采用结构光的方式去实现Animoj。而快手是国内较早实现不使用结构光,只用RGB图像信息就实现Animoji效果的企业。

用户不必去花上万元去买iphoneX,只要用一个千元的安卓手机,就可在快手的产品上体验Animoji的特效,从而能够在不暴露脸部信息的同时展现细微的表情变化,例如微笑、单只眼睛睁单只眼睛闭等,让原来一些羞于表演自己才艺的人,也可以非常自如地表达。我们觉得做技术有一个非常快乐的事情,就是让原来少数人才能用的技术,变得更普惠。

其实解决这样一个问题是非常难的,因为即使是像苹果这样的公司,也是采用了结构光这样配置额外硬件的方式来解决。想让每一个用户都能享受到最尖端的技术,快手面临着硬件的约束,只能通过2D的RGB视觉信息对问题进行建模、求解,这里面包括了像Landmark人脸关键点检测、实时重建人脸三维模型等技术,把2D和3D两种不同模态的信息做建模、做对齐。
我们也能看到现在市场上可能有一些小型的APP在做类似的事情,但体验很差,而我们的整体体验还是非常好非常流畅的,这也需要归功于深度神经网络模型的量化,通过压缩和加速解决手机性能问题,可适配任意机型。
多模态技术如何实现精准理解视频内容
刚才我讲的是我们多模态技术怎样去帮助用户更好地记录,我们同时也希望通过一个更好的分享机制,让用户发布的视频能够被更多感兴趣的人看到。这也涉及视频推荐里面多模态的一些问题。