基于网格的表示。目前有3种主要的网格表示类型:体素、柱体和BEV特征图。
体素。体素是3D立方体,体素细胞内包含点。点云可以很容易地通过体素化转化为体素。由于点云分布稀疏,3D空间中的大部分体素细胞都是空的,不包含点。在实际应用中,只有那些非空体素被存储并用于特征提取。VoxelNet[359]是一项利用稀疏体素网格的开创性工作,提出了一种新的体素特征编码(VFE)层,从体素细胞内的点提取特征。
此外,还有两类方法试图改进用于3D目标检测的体素表示:
- 多视图体素。一些方法从不同的视角提出了一种动态体素化和融合方案,例如从鸟瞰图和透视图[360],从圆柱形和球形视图[34],从深度视图[59]等。
- 多尺度体素。一些论文生成不同尺度的体素[323]或使用可重构体素。
柱体。柱体可以被视为特殊的体素,其中体素的大小在垂直方向上是无限的。通过PointNet将点聚集成柱状特征[207],再将其分散回去,构建二维BEV图像进行特征提取。PointPillars[117]是一个开创性的工作,介绍了柱体表示,随后的是[283,68]。
BEV特征图。鸟瞰特征图是一种密集的二维表示,其中每个像素对应一个特定的区域,并对该区域内的点信息进行编码。BEV特征图可以由体素和柱体投影到鸟瞰图中获得,也可以通过汇总像素区域内的点统计数据,直接从原始点云中获得。常用的统计数据包括二进制占用率[314,313,2]和局部点云高度和密度[40,10,342,3,245,346,8,119]。
基于网格的神经网络。目前主要有两种基于网格的网络:用于BEV特征图和柱体的2D卷积神经网络,以及用于体素的3D稀疏神经网络。
与BEV特征图和柱体2D表示相比,体素包含更多结构化的3D信息。此外,可以通过3D稀疏网络学习深度体素特征。但是,3D神经网络会带来额外的时间和内存成本。BEV特征图是最有效的网格表示,它直接将点云投影到2D伪图像中,而无需专门的3D算子,如稀疏卷积或柱体编码。2D检测方法也可以在BEV特征图上无缝应用,无需太多修改。
基于BEV的检测方法通常可以获得高效率和实时推理速度。然而,简单地汇总像素区域内的点统计信息会丢失太多的3D信息,与基于体素的检测相比,这会导致检测结果不太准确。
基于柱体的检测方法利用PointNet对柱体单元内的3D点信息进行编码,然后将特征分散回2D伪图像中进行有效检测,从而平衡3D目标检测的效果和效率。
选择合适大小的网格单元是所有基于网格的方法都必须面对的关键问题。通过将连续点坐标转换为离散网格索引,网格表示本质上是点云的离散形式。在转换过程中不可避免地会丢失一些3D信息,其效果很大程度上取决于网格单元的大小:网格小,分辨率高,可以保持更细粒度的细节,对于准确检测3D目标至关重要。然而,减小网格单元又会导致2D网格表示(如BEV特征图或柱体)的内存消耗呈二次方增长。至于像体素这样的3D网格表示,问题可能会变得更加严重。因此,如何平衡更小网格尺寸带来的效果和内存增加影响效率,仍然是所有基于网格的3D目标检测方法的一个挑战。
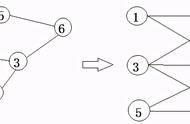
3、基于Point-Voxel的3D目标检测方法基于点-体素的方法采用了一种混合架构,利用点和体素进行3D目标检测。主要分为两类:单阶段检测框架和两阶段检测框架。下图显示了这两个类别的示例及分类:


单阶段基于点-体素的3D目标检测器通过骨干网络中的点-体素和体素-点的变换来连接点和体素的特征。点包含细粒度的几何信息,体素计算效率高,在特征提取阶段将它们结合在一起更加有利。代表性工作包括:PVCNN、SPVNAS、SA-SSD、PVGNet等。
两阶段的基于点-体素的3D目标检测器,在第一阶段,使用基于体素的检测器来生成一组3D候选目标。在第二阶段,首先从输入点云中采样关键点,然后通过新的点算子对关键点进行进一步细化。代表工作包括:PV-RCNN、LiDAR R-CNN、Pyramid R-CNN、CT3D等等。
与纯体素检测方法相比,基于点-体素的3D目标检测方法在增加推理时间的同时,可以获得更好的检测精度。
4、基于Range的3D目标检测Range图像是一种密集而紧凑的2D表示,其中每个像素包含3D深度信息,而不是RGB值。需要针对Range图设计模型和算子,并要选择合适的视图。