你肯定很熟悉以下情况:你下载了一个比较大的数据集,并开始分析并建立你的机器学习模型。当加载数据集时,你的计算机会爆出"内存不足"错误。
即使是最优秀的人也会遇到这种事。这是我们在数据科学中面临的最大障碍之一,在受计算限制的计算机上处理大量数据(并非所有人都拥有Google的资源实力!)。
那么我们如何克服这个问题呢?是否有一种方法可以选择数据的子集并进行分析,并且该子集可以很好地表示整个数据集?
这种方法称为抽样。我相信你在学校期间,甚至在你的职业生涯中,都会遇到这个名词很多次。抽样是合成数据子集并进行分析的好方法。但是,那我们只是随机取一个子集呢?
我们将在本文中进行讨论。我们将讨论八种不同类型的抽样技术,以及每种方法的使用场景。这是一篇适合初学者的文章,会介绍一些统计的知识
目录- 什么是抽样?
- 为什么我们需要抽样?
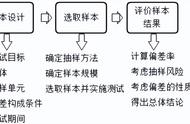
- 抽样步骤
- 不同类型的抽样技术
- 概率抽样的类型
- 非概率抽样的类型
让我们从正式定义什么是抽样开始。
抽样是一种方法,它使我们能够基于子集(样本)的统计信息来获取总体信息,而无需调查所有样本。

上图完美地说明了什么是抽样。让我们通过一个例子更直观的进行理解。
我们想要找到Delhi这个城市所有成年男性的平均身高。Delhi的人口大约为3千万,男性大约为1500万(这些都是假想数据,不要当成实际情况了)。你可以想象,要找到Delhi所有男性的身高来计算平均身高几乎是不可能的。
我们不可能接触到所有男性,因此我们无法真正分析整个人口。那么,什么可以我们做的呢?我们可以提取多个样本,并计算所选样本中个体的平均身高。

但是,接下来我们又提出了一个问题,我们如何取样?我们应该随机抽样吗?还是我们必须问专家?
假设我们去篮球场,以所有职业篮球运动员的平均身高作为样本。这将不是一个很好的样本,因为一般来说,篮球运动员的身高比普通男性高,这将使我们对普通男性的身高没有正确的估计。
这里有一个解决方案,我们在随机的情况下随机找一些人,这样我们的样本就不会因为身高的不同而产生偏差。
为什么我们需要抽样?我确定你在这一点上已经有了直觉的答案。
抽样是为了从样本中得出关于群体的结论,它使我们能够通过直接观察群体的一部分(样本)来确定群体的特征。
- 选择一个样本比选择一个总体中的所有个体所需的时间更少
- 样本选择是一种经济有效的方法
- 对样本的分析比对整个群体的分析更方便、更实用
将概念形象化是在记忆的好方法。因此,这是一个以流程图形式逐步进行抽样的流程图!